
要是这事是确实,那真不是“性能普及”,而是班师把AI的底层限定掀桌子。
就在春节期间,一家名为Taalas的新芯片公司一霎冒出来,干了一件顶点到近乎猖狂的事——把大模子班师“烧”进芯片里。
不是优化推理框架,不是堆显存,不是上更高带宽,而是透顶烧毁通用性,把模子自身固化为硬件。
简便来说即是,传统GPU是通用算力平台。
你不错在NVIDIA的H200、B200上跑不同模子,今天Llama,翌日Claude,后天我方锻练的非凡模子,软件层转移,硬件层算力兜底。这套体系强在天真,代价是带宽墙、访存瓶颈、功耗飙升。
Taalas走的是另一条路:不作念“通用算力”,只作念“特定模子算力”。模子结构、权重映射、数据旅途一谈在芯片想象阶段就细目,绕开GPU最致命的那谈坎——内存带宽。
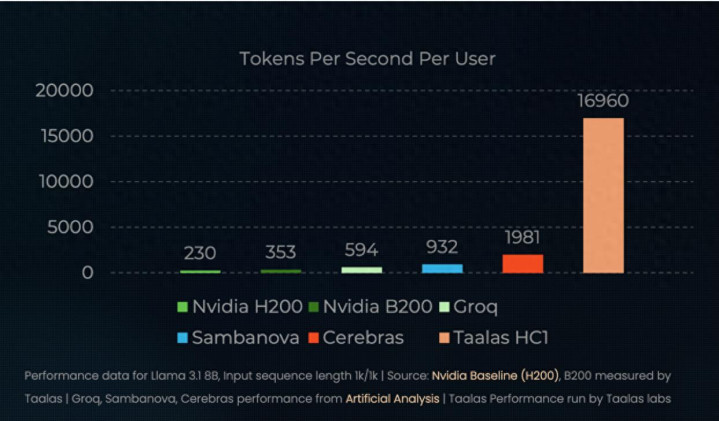
公开演示中,这颗芯片在腹地开动Llama 3.1,速率达到17000 token/秒。看成对比,H200简易在200多token/秒量级,B200在2000 token/秒控制。
哪怕不同测试环境、优化进度有各别,这个数目级差距还是夸张。它不是快少许,是从“及时对话”跳到了“瞬时反应”。
背后的逻辑并不好意思妙。大模子推理,本体上是大齐矩阵乘法和参数读取。GPU的问题在于:算力弥散,但每一步齐要从显存搬权重,数据流动远比狡计自身耗时。
{jz:field.toptypename/}Taalas的想路,是把权重班师镶嵌芯片结构,让“读取”这个动作物理隐没。算力不再被带宽卡脖子,蔓延当然断崖式下落。
代价也很明确——通用性简直为零。升级模子?换芯片。想换算法?换芯片。
它像一台只可玩一款游戏的机器,性能炸裂,但不成插卡带。这种想象在滥用级商场简直无法开发,但在特定场景下,开云体育反而是优点。

比如云推理巨头。亚马逊、谷歌、微软每天要跑海量固定模子央求。
要是某个模子调用频率极高,定制化硬件意味着本钱、功耗、机房压力全线下落。只有模子版块更新节律可控,换一批板卡并不是不可经受的代价。
再往深一层看,着实明锐的是安全和细目性。军事、工业摈弃、自主系统,对“可瞻望行径”的条目远高于天真性。
一个只可开动指定模子、无法被外部点窜的芯片,本体上是硬件级黑盒。挫折面松开,系统结识性提高。这种“功能焊死”的特质,在某些场景反而是刚需。
自动驾驶和机器东谈主一样值多礼贴。刻下自动驾驶链路是“感知—有策划—执行”,中间的推理蔓延决定安全限度。

要是推理蔓延压缩到毫秒级以致更低,系统反应接近生物反射,想象空间会被再行翻开。
虽然,这里需要从容少许——车辆系统瓶颈不单在模子推理,还包括传感器、摈弃系统、物理制动距离。芯片再快,也不成违背物理寰宇。
着实的冲击在产业结构。
当年几年,AI基础法式简直等同于英伟达生态。CUDA、显存、带宽、NVLink,组成了难以撼动的护城河。
Taalas的出现,提供了一个想路:要是欢畅烧毁“什么齐颖异”,就不错在本钱和功耗上完了数目级糟塌。
这不是取代GPU,而是切分商场。通用锻练仍然属于GPU,天真多模子部署仍然需要通用算力。但在高频、固定模子推理场景,定制芯片可能是另一条弧线。

AI制图
风险一样存在。模子迭代速率极快,从Llama 2到3再到3.1,只用了很短时候。
要是模子更新快于硬件更换周期,这套口头会被反噬。硬件固化意味着策略押注,一朝押错模子,库存即是负钞票。
是以它更像一枚宗旨性信号:在制程面对物理极限、算力增长放缓的布景下,架构改造仍有空间。不是每一次糟塌齐来自更小的晶体管,无意来自对“通用”二字的反想。
要是将来几年咱们看到更多“模子即芯片”的家具,无谓惊诧。这是算力产业从疏忽堆叠,走向场景分化的势必阶段。
真适值多礼贴的,不是17000 token/秒这个数字自身,而是一个问题——当算力不再是瓶颈,谁来界说AI的限度?
 备案号:
备案号: